
Paper.Yellow
2. 데이터베이스 개요 본문
1. 데이터베이스
Data + Base = 자료 + 저장장소 <-> 정보와 데이터는 다름.
2. 파일시스템의 단점을 극복하기 위해 나옴.
- 다수 사용자 접근 불가능.
- 데이터 무결성(일관성,중복,정확성)을 확보할 수 없음.
- 데이터 공유 불가능.
3.DBMS
-데이터베이스 관리 시스템
(캐시는 상대적. 캐싱 메모리 ) I/O 관점에서 중요한거. 다음이 알고리즘
LRU 가장 최근에 사용하지 않은 메모리를 삭제?
OLTP 실시간 처리. 자주 처리하기 때문에 정보가 메모리에 할당되어 있어야한다.
OLAP 정산 처리 한번에 처리하기 때문에 메모리에 정보가 있을 필요가 없다.
키워드는 대문자
이 테이블이 가지고 있는 구조 = 스키마
스키마를 봐야지 열을 선택할 수 있다. 스키마를 모르고 값을 입력할 수 없다. 타입을 알 수 없음.
열을 고르는 행위 프로젝션
SQL 구조적 지리 언어 (Structured Query Language)
DB를 관리(지휘)하는 언어, DSL(도메인 특화 언어)범주화가 되어 있다.
4. 쿼리 실행 순서
- FROM
- WHERE
- GROUP BY
- SELECT
- ORDER BY
쿼리의 우선순위
SELSCT 가상의 값을 프로젝션 할 수 있는데 정렬을 먼저 하면 그 값을 적용할 수 없다.
▶SELECT 프로젝션, 열을 추출
● 필요한 행의 이름을 입력하기
● * 로 모든 값 호출
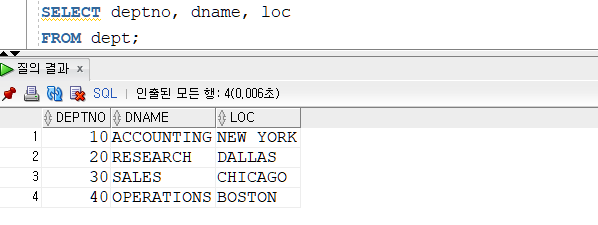
▶FROM 테이블을 가져온다.

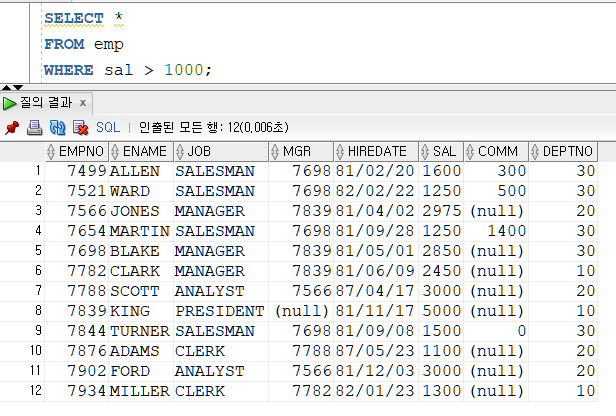
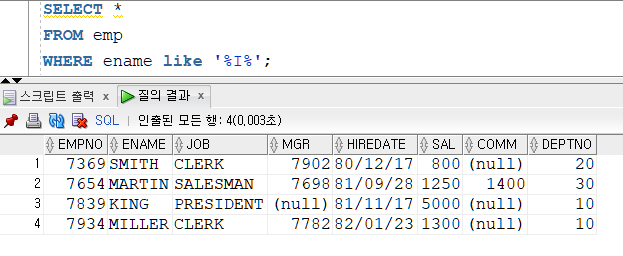
▶ WHERE 행을 추출하기





▶ORDER BY 정렬
EDSC 내림차순, ASC 오름차순
최대한 안 쓰는게 좋다.









'데이터베이스' 카테고리의 다른 글
| MySQL 시간 입력하기 (0) | 2022.12.06 |
|---|---|
| 쿠키 (0) | 2022.09.16 |
| 5.JAVA(이클립스)로 DB(오라클)연결하기 (0) | 2022.08.16 |
| 1. 데이터베이스 (0) | 2022.08.09 |

